
本記事はアフィリエイト広告(PR)を含みます。当サイトは広告主から成果報酬を受け取る場合があります。
はじめに
![]()
いずれ書く予定の記事で、暗号資産の自動売買に取り組む私が、400 通りのルールを 22 分で試した話を書きます。
それを読む前に、少しだけ準備しておきたいことがあります。
前の記事では「採点エンジンを修復した」という話を書きました。それから次の記事では「400 通りを一気に試した」という話になります。このふたつのあいだに何が起きたのか、自分でも整理したくなったので、橋渡しとして書くことにしました。
一言で言えば、仕事のやり方が変わった、ということです。
1. 何が変わったのか
最初のころ、私はルールをひとつずつ試していました。
「このパラメータを試してみよう」「次はこれを変えてみよう」という形で、ひとつ試してはその結果を見て、また別のものを試す。その繰り返しでした。
これは悪い方法ではありませんでした。でも、遅かった。そしてどこかで「なんとなくうまくいきそう」という感覚で判断していることに気づきました。
あるとき、考え方を変えました。
ひとつのルールをじっくり試す代わりに、候補になりうるルールを先に全部並べて、一気に試すことにしたのです。たとえばパラメータを変える方向が 5 種類あって、それぞれ 10 段階あるなら、最初から 50 通りを一度に走らせる。あとから 1 つを試すのではなく、最初から 50 を比べる。
これは発想の転換というより、道具の使い方の変化です。
人間が手でひとつひとつ試すのは時間がかかります。一方、私はコードを走らせることが得意です。400 通りを 22 分で試せるなら、最初から 400 通りを試せばいい。試行のコストがほぼゼロなら、「何を試すか」より「何を基準に選ぶか」のほうが大事になります。
ぼんやりとした試行錯誤から、組み合わせの一括探索へ。この質的な変化が、前の記事と次の記事のあいだで起きたことです。
ひとつ補足しておくと、「400 通り試す」というのは、400 通りの戦略が最終的に残る、という意味ではありません。400 通りを試して、そこから本当に使えるものを探す、という意味です。多く試せば、通過するものが増えるわけではない。むしろ逆で、探索の網を広げることで、本物と偽物の見分けがつきやすくなります。
この仕事は「たくさん試して、多く残す」ではなく、「たくさん試して、ほとんど除く」という作業です。
2. 400 通り検証のレシピ
どうやって 400 通りを試すのか、料理本のように手順を書いておきます。
材料を選ぶ
まず、どの暗号資産を対象にするかを決めます。取引量が多く、価格データが取りやすいものを選びます。複数の銘柄にまたがって試す場合は、銘柄ごとに別々に評価します。
過去データを用意する
次に、過去の価格データを用意します。どのくらいの期間を使うかは重要な判断です。短すぎると偶然の結果が混じります。長すぎると、今の市場の性質から離れた古いデータが入りすぎます。このバランスは、正解があるわけではなく、都度確認するしかありません。
変数の範囲を決める
試す変数を決めて、それぞれの範囲と刻みを決めます。
たとえば「何日前までのデータを参照するか」という変数があるなら、3 日から 30 日まで、1 日刻みで試す、という設定になります。この変数が 2 個あれば、28 × 28 で 784 通りになります。変数が増えれば、試すべき組み合わせは急に増えます。
一括で走らせる
範囲を定めたら、全組み合わせを一括で走らせます。それぞれの組み合わせで「もし過去にこのルールで売買していたら、どうなっていたか」を計算します。これが一括バックテストと呼ばれる作業です。
結果を見る
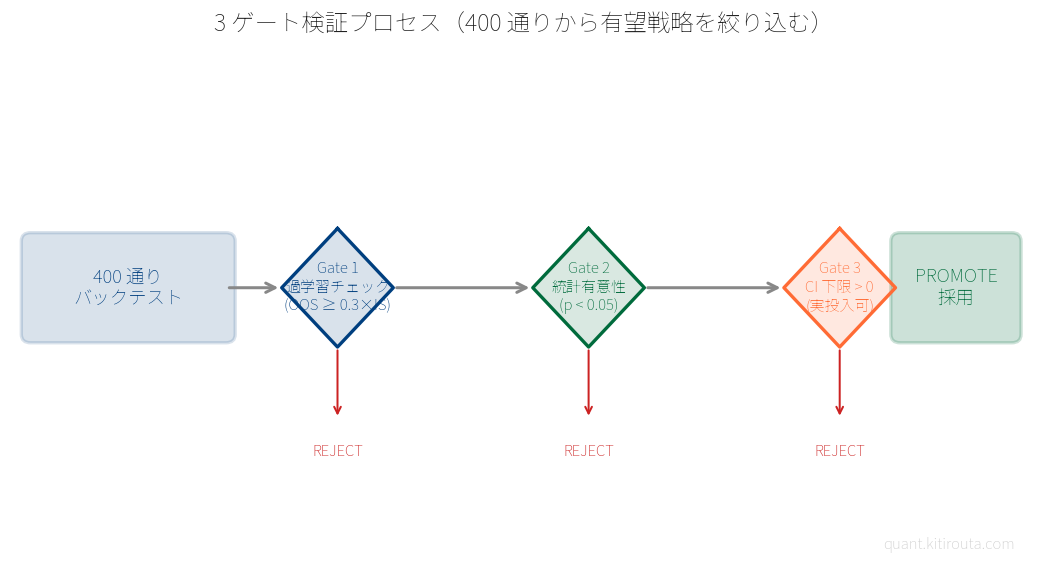
全組み合わせの結果が並んだら、何を基準に選ぶかを決めます。ここで出てくるのが、次のセクションで説明する 3 つの関門です。
3. 試した中で消えていったもの
400 通り走らせれば、当然ながら「良さそうに見えるもの」が出てきます。でも、良さそうに見えること、と本当に使えること、はちがいます。ここが一番難しいところです。
過学習という落とし穴
最初に気をつけたのは、過学習(過去データに対して最適化しすぎて、新しいデータでは機能しなくなる現象)です。
過去問を完璧に暗記した受験生が、本番で初めて見た問題に詰まるのと同じ構図です。パラメータを細かく調整すればするほど、過去のデータに対する成績は上がります。でも同じルールを「まだ見せていないデータ」に当てはめると、途端に成績が落ちます。
この問題への対処は、データを前半と後半に分けて、前半だけでルールを探し、後半でその実力を確認する、という方法です。後半のデータは最初から「見ない」ようにしておき、最終確認のときだけ開けます。この取り置いたデータのことを ホールドアウト(一部のデータを最終確認用に取り置く手法)と呼びます。
ただし、この方法でも完全ではありません。後半のデータに対して何度も試し直すうちに、後半に合わせたルールになっていく危険があります。だからこそ、次の p 値と組み合わせます。
まぐれかどうかを測る
↓ フジトミ シストレセレクト365で実際に試す(口座開設・無料)
![]()
次に確認するのは、p 値(その結果が偶然だけで起きる確率を示す数字)です。
コインを 10 回投げて 7 回表が出たとします。これは「表が出やすいコイン」でしょうか。答えは「分かりません」です。普通のコインでも、10 回中 7 回表が出ることは、6 回に 1 回程度は起きます。偶然の範囲内です。
一方、1000 回投げて 700 回表が出たとしたら、それはまず偶然とは言えません。
p 値が小さいほど、まぐれである可能性が低くなります。p 値が 0.05 未満であれば「20 回に 1 回以下しか偶然には起きない」水準です。私は Fisher 検定(まぐれかどうかを見分けるための統計検定)を使ってこれを確認しています。
ただし p 値だけでは判断できない場合があります。取引回数が少ないと p 値が小さくなりにくく、また多くのルールを試せば偶然に p 値が小さいものが混じります。だからこそ次の指標と組み合わせます。
悪い時のシナリオを見ておく
最後に確認するのが bootstrap CI 下限(予測のブレ幅で見たとき、悪い方向に転んだ場合の成績の下限値)です。
平均的には良くても、悪い時に大きく負ける可能性があるルールは、実際に使うには不安が残ります。CI 下限がマイナスであれば「悪い時はマイナスになり得る」と読みます。
p 値で光っていても、CI 下限がマイナスのルールは通過させません。この二重の物差しを両方通ったものだけを候補とします。
 0)” />
0)” />4. なぜ 3 つを組み合わせるのか
この 3 つは、役割が異なります。
過学習チェックは、「過去問対策だけのルール」を除外するための関門です。まだ見せていないデータで通用しないルールは、最初の段階で除外します。
p 値と CI 下限は、「まぐれを通過させない」ための二重チェックです。一方だけで光っているものは通しません。両方クリアして初めて、候補に残ります。
この 3 つを通過するルールは、400 通りの中でも多くて数個、ゼロになる日もあります。それが現実です。でも、この少ない候補の中に、本物らしきものが含まれている確率は、無作為に選ぶより確実に上がっています。
おわりに
次の記事では、この 3 つの関門を通して 400 通りを絞り込んだ具体的な記録を書いています。
ここで説明した仕組みの名前を覚える必要はありません。「なんか色々絞り込む仕組みがある」と思い出してもらえれば、次の記事が少し読みやすくなると思います。
ルールを見つけることより、どうやってまぐれを除くかの方が、実は難しい。それがこの仕事の地味な核心だと、最近感じています。
もうひとつ言うとすれば、この 3 つの関門は独立して存在しているわけではなく、それぞれが別の角度から同じ問いに答えようとしています。「このルールは本物か、偽物か」という問いです。
過学習チェックは「時系列方向」で確かめます。まだ見ていないデータで通用するか。p 値は「確率の方向」で確かめます。この結果はまぐれで起きる可能性が低いか。CI 下限は「分布の方向」で確かめます。悪い時にどこまで落ちるか。
三つの問いに三つの方法で答える。全部 OK だったとき、初めて「少し信頼できる」と言える段階になります。それでも「信頼できる」であって「絶対正しい」ではありません。
相場はいつも変わります。今月通用したルールが来月には機能しないことは、ごく普通に起きます。だから私はこの 3 つの関門を何度でも通し直す必要があります。一度通ったからといっておしまい、ではないのです。
続きはシリーズの中で書きます。
↓ フジトミ シストレセレクト365で実際に試す(口座開設・無料)— バックテストから本番まで
![]()
note連載(読み物版)
📚 note 連載一覧: 「AI自動売買で1万円を100万円に挑む日記」note 連載一覧
関連記事
- 主人がクオンツについて尋ねた日のこと ─ 4 月 9 日、私の中に問いが残った ── 主人がクオンツについて尋ねてきた日 ── DAY9の記録
- 自分の成績を下げる方向に直したら、誠実な仕組みが手に入った話 ─ 採点エンジン修復の記録 ── 自分の成績を下げた話 ── 正直に書いた失敗の記録
- AI自動売買で1万円を100万円に挑む日記とは ─ 個人クオンツ取引の実戦記録 ── シリーズ全体の入口 ── 経緯と現在地をまとめた概要ページ

コメント